Depth-First Search Maze Generation
There are quite a few approaches for generating mazes algorithmically. I particularly like the graph based approaches, since they seem most adaptable. They are:
- Using a MST algorithm (like Prim’s or Kruskal’s) on a randomly weighted graph.
- Performing a depth-first search on a graph, with some randomness built into the algorithm.
Maybe there are even more graph-based maze generation methods, but I don’t know about them. There are of course some non-graph-based methods, like iteratively splitting a space into randomised chunks and cutting holes in the new walls1, or even using cellular automata2, which are also interesting.
The reason I say that graph based approaches are most adaptable is because of their independence on any particular shape or structure. You’ll see what I mean by this later on.
Defining a Maze
First it might be a good idea to define what a maze is and isn’t. For example, consider this:

Imagine that the black lines are passageways that you can walk through. This definitely seems like a maze. Here are some properties of this specific maze:
- No loops/cycles: there is exactly one route from any one location to any other.
- There are no disconnected sections: any point is reachable from any other point.
- No obvious-at-a-glance route from a point to another far-ish-away point.
The last of these is the most controversial of the three, since it’s very difficult to quantify how difficult a maze is. However, here are some features of good mazes that probably help:
- No repeating patterns, as these would make visually parsing the maze more manageable.
- No excessively long straight corridors/lots of bends makes following paths more tricky.
- Many points where passageways branch, meaning that someone solving the maze has to check a lot of different routes.
Probably none of these features are necessary for something to be a maze, though. Loops are definitely possible in mazes, there’s no reason why not, and the only reason they’re not present in the above maze is because it is specifically a spanning tree of a graph. Mazes may in theory have disconnected sections, I suppose, but in that case it would really just be two (or more) mazes next to each other. Also, mazes don’t need to have a non-obvious solution – take the kids mazes on the backs of some ceral boxes, for example.
In fact, mazes don’t even need to have branches. Some hedge mazes3, for instance, are just one long twisting path from start to finish. And should all mazes have a start and a finish? The maze presented above doesn’t have a specific start or finish, but the nature of it means that any two points on it can reasonably be chosen for these. I would say that a maze has to have a defined start and finish, or be constructed such that they can be chosen arbitrarily.
I think a reasonable definition for a maze is just “A passageway (or collection of passageways) connecting a start to a finish”. Then if our maze has starts and finishes that can be chosen arbitrarily, we basically have a set of mazes with the same construction but with different start and finish points. Anyway, this doesn’t matter.
Depth-First Search
The maze-generation algorithm I’m going to talk about now is depth-first search (DFS). This algorithm is used for many more useful purposes than generating mazes, but this is what I’ll use it for.
DFS takes a graph (a collection of nodes and edges between them) and a starting node, and, in a certain order, examines each of these. The reason it’s called “depth-first” is that it starts by traversing one path for as long as possible before going back to try another one. This is in contrast to breadth-first searching which, before examining any node which is n nodes away from the starting node, examines all those which are up to n-1 away.
This post isn’t meant to be a detailed depth-first search tutorial – you can easily find those anywhere on the internet. Even still, here’s some rough pseudocode for one iteration of the algorithm, as I implemented it for this purpose:
PROCEDURE dfs_step
INPUTS:
G: The graph to search
S: A stack data structure.
WHILE S is not empty
next = S.pop()
IF `next` has not yet been visited:
Visit `next`
FOR EACH edge IN `next`'s neighbours:
S.push(`edge`)
RETURN
This is slightly different to standard iterative DFS implementations, in that the procedure only executes one step, by which I mean it runs until it either exhausts the stack or a new node is visited. Normal implementations run until the entire graph has been visited.
The reason for this difference is that I wanted to display a realtime animation of the algorithm running, and this implementation allows me to periodically run a step (say, every half a second) and update the graphical representation accordingly, without the algorithm itself needing to know anything about this.
To summarise the pseudocode, we repeatedly pop nodes from the stack until we find one that we haven’t visited yet. Then, we “visit” it, push all of its neighbours to the stack, and return, i.e. end the procedure. A traditional DFS implementation won’t return at this point, as I mentioned earlier, and instead will repeat until there’s nothing left on the stack.
The meaning of “visiting” a node depends on what the DFS is meant to achieve. For example, another use of DFS is finding connected components within a graph. To do this, we can just begin a DFS at an arbitrary node, and efficiently find the connected component that contains it, then repeating the process on an unclassified node. In such a case, “visiting” a node would be adding it to a list of nodes in some structure representing the connected components of a graph.
What about generating a maze, though? If we run DFS on any graph and make a note of the order in which nodes are visited, we can construct a tree containing every node. Let’s run through a quick example.
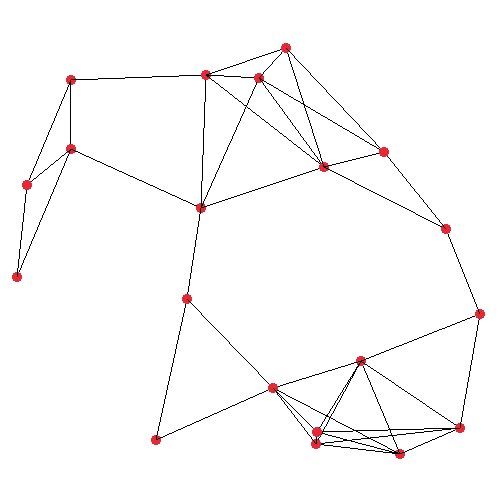
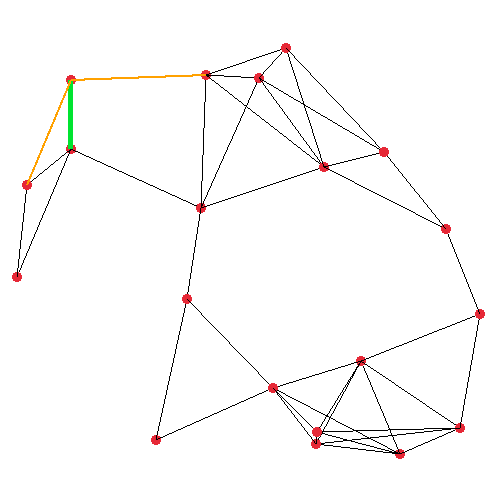
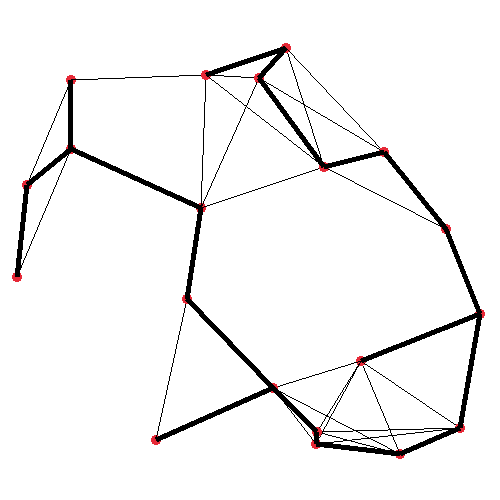
The first image shows the plain graph which we’ll operate on. I generated this graph by randomly placing 20 nodes in a 500×500 unit space, and mutually connecting any two nodes which are closer than (or exactly) 150 units apart. The second image visualises the very first iteration of my DFS step procedure. It’s starting at the top-left node, where the orange and green lines are protruding from, which represent all of the node under consideration’s neighbours. The actual implementation pushes the edges such that the closest edge is at the top of the stack.
In the third image, in bold, the resulting spanning tree is shown. It may not look much like a maze at this point, but the point is we can run this on any graph, and certain graphs will yield better mazes. In fact, the big square maze presented earlier in this post was generated in the exact same way as this tree. The primary difference between these two, and all the other mazes I’ll make, are in the way the graph is generated initially, although I make a couple of extra modifications to the algorithm as well, for some.
Grid-like Maze
A very standard type of maze is square-shaped, with horizontal and vertical passageways. I can very easily write a function to place nodes in a square grid, and join them to their correct neighbours. Then I can just feed this graph into the DFS algorithm, and…

Oh, it’s not a very good maze. Going back to my thoughts earlier about what makes a (good) maze,
we can see that this one has no cycles and no disconnected sections, like the earlier maze, but,
it’s very easy to solve this maze from any point A to any point B. In fact it’s trivial, because
this maze has no branches at all – it’s topologically equivalent to a straight line. Starting from
A, you can always get to B, regardless of where B is, by just trying each of the two opposite directions.
In fact this maze is even worse than just the general case of mazes topologically equivalent to
straight lines, because it has a consistent repeating zig-zag pattern going downwards, so if you
know the positions of A and B you can immediately know whether you have to travel up or down in space,
and hence work out if you need to start moving left or right. In other words, with this maze, it
would be possible to implement a function Node next_node(Node current_node, Node to_find) that
runs in O(1) time, given that we can view the structure of the maze from above.
The reason that our algorithm generates a zig-zag maze here is just because we don’t involve any randomness yet. The procedural method by which we generated our graph appends neighbouring nodes to a list contained within each node, and this list is iterated in order when pushing to the stack in the DFS algorithm. The way that this list is generated means that neighbours are pushed in the order (up, down, left, right), and so if a right-facing neighbour is present, this will always be preferred (because it will be at the top of the stack at the start of the next iteration). This explains the intial long-as-possible right-facing path. It only stops moving right when it can’t anymore, because that neighbour is then not pushed to the stack.
The solution is simple though, we can just shuffle each node’s neighbour list at initialisation time. And this pattern has the added benefit that it’s adaptable to different patterns that we might want. For example, remember what I mentioned earlier about picking the neighbour closest to the current node, when we saw the DFS algorithm running on a more freeform graph layout? Well that behaviour doesn’t have to be impemented within DFS at all, keeping it more generalised. Instead we implement that in the same way as this neighbour shuffling, by sorting each node’s neighbours list by distance, specifically for graphs where we want this shortest-first behaviour.
Anyway, if we implement this neighbour shuffling, we get this:

This is significantly better. Now, we have lots of branching – this occurs when a search path gets to a point where it cannot go any deeper, so it pushes no neighbours for the next iteration and instead some neighbours that were pushed by an earlier iteration are taken instead.
This maze still isn’t ideal though. The branches, although many, are not, on average, very deep, which makes it easy to quickly disregard many of them when solving the maze. I think this is just because this particular maze is fairly small. If I generate a larger one, the branches become far longer.

Customising The Maze
It can be fun to fiddle with the code a bit to get some different interesting mazes. With our graph-based maze approach, there are a lot of options here, because we simply apply our algorithm to any graph.
Grid-Like Mazes
First, let’s look at different ways we can modify our existing grid maze.


The only change needed to generate these three mazes is to change which nodes count as neighbours of other nodes. Before, a node only neighboured adjacent nodes cardinally north, east, south, and west of it, but this can easily be changed when generating the graph.
For the first of these three examples, the neighbourhood includes all eight adjacent nodes, including diagonals. This produces maybe a more “organic” looking design. It also kind of reminds me of runes in some fantasy game?
In the second example, the four cardinal directions are included, as well as north-west and south-east neighbours. This creates angles paths, and almost looks like a normal maze has just been skewed.
The third example is similar, except depending on the node’s position on the y-axis the “skew” direction is either left or right.
“Loose” Graph Layout
As shown earlier, we can generate a maze on top of any graph, not only rigid grids. For these next tests, I place 1000 nodes randomly in a 800x800px world.


To determine the neighbours, the first of these two examples finds all other nodes which are within a certain threshold distance (in this case 100px), and uses this set as its neighbourhood. The ordering of these neighbours (which determines how DFS will traverse the graph – remember how we randomised the ordering of neighbours for the rigid grid earlier) is simply their distance. The shortest node comes first in the neighbour order.
This means that we get lots of winding, intricate paths, since it’s biased towards picking out small details.
In the second example, the set of neighbours is generated identically (though with a different random seed). The only difference is that instead of ordering the neighbours by their distance, they’re just shuffled (exactly like the earlier rigid grid examples). Since here we have a combination of a fairly high threshold and densely packed nodes, we get a bit of a mess here. I think it looks like the creases of scrunched up tin foil.
If you experiment with this yourself, it’s fun to play with the density and threshold parameters for the loose graph. If the nodes are too sparse, though, there is a chance that you’ll encounter disconnected regions, meaning that the whole graph will not be part of the maze.
Some nice things to do to extend this would be:
- Some constraint for a minimum distance between two nodes. At the moment, two nodes may spawn almost touching, which can make the resultant maze look like it contains cycles even when it doesn’t.
- A neighbourhood ordering function which takes into account distance but applies some randomness on top of this.
Aside on overlapping passages: When I first ran a version of this “loose maze” generator, sometimes passages would overlap. This was of course because the neighbourhood generation didn’t take this into account, and the DFS algorithm itself didn’t check for overlaps either.
I had the option of either ensuring no overlaps when generating the ‘substrate’ graph, or making a DFS which is aware of this. I decided on the latter, since whether an edge may exist without overlapping only depends on previous edges that have been visited.
Other Fun Shapes
The current state of the program supports grid mazes and loose mazes, and some code to try and generate a labyrinth-like maze (where nodes lie on concentric circles, with a few edges between them). The labyrinth generator isn’t working that well at the moment – ideally, I want fully the concentric circles to have long unbroken sections, with far fewer inter-ring connectors.
Below, my radial graph is on the left, and on the right is something that I would like mine to look like! One major difference here is that the target image uses lines as walls, whereas mine uses lines as passages. I think that DFS might not be the correct algorithm to use to generate this sort of maze, anyway.


If you’re interested in this, you should definitely have a go at writing your own code to generate graphs. Here are some ideas:
- Fix my labyrinth implementation.
- Make a maze which resembles an image, or some text.
- Generate a voronoi diagram, and use its interface lines as edges.
You can find the source code on GitHub!
Final Thoughts
Depth-first search on a graph can generate some quite nice custom mazes. Since it’s “depth-first”, though, there is some bias towards long paths, which may or may not be desirable. Other algorithms (such as a greedy MST algorithm or a breadth-first search) will have different characteristics in this way, which might be better for some applications.
References
-
Hedge mazes in particular always have the other kind of branch, though. ↩
Written 21 Nov 2023 by Jacob Garby